FramePack 降低 AI 视频生成硬件门槛,6GB 显存即可生成 60 秒视频
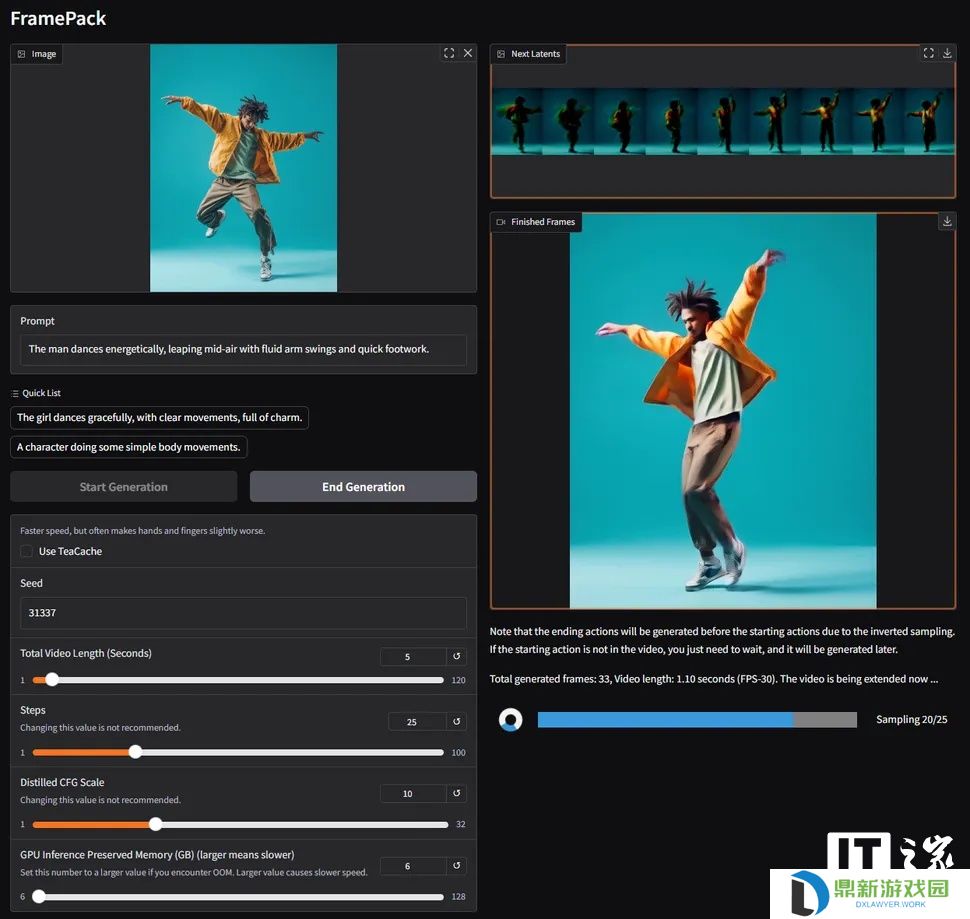
本站 4 月 20 日消息,来自 GitHub 的 Lvmin Zhang 与斯坦福大学的 Maneesh Agrawala 合作,共同推出了一项名为 FramePack 的创新技术。该技术通过采用固定长度的时域上下文(fixed-length temporal context)对视频扩散模型(video diffusion)进行了实用化实现,显著提高了处理效率,使得在较低硬件配置下生成更长、更高质量的 AI 视频成为可能。基于 FramePack 架构构建的一个 130 亿参数模型,仅需 6GB 显存即可生成长达 60 秒的视频片段。

据本站了解,FramePack 是一种神经网络架构,其核心优势在于利用多阶段优化技术,有效降低了本地运行 AI 视频生成任务对硬件的要求。据报道,目前 FramePack 的图形用户界面(GUI)内部运行的是一个定制的、基于混元(Hunyuan)的模型,但研究论文同时指出,现有的预训练模型也可以通过 FramePack 技术进行微调以适配该架构。
传统的视频扩散模型在生成视频时,通常需要处理先前生成的所有带噪帧(noisy frames)数据来预测下一个噪声更少的帧。这个过程中所参考的输入帧数量被称为“时域上下文长度”,它会随着视频长度的增加而增长。这导致标准的视频扩散模型对显存(VRAM)有着极高的要求,通常需要 12GB 甚至更多。虽然可以通过降低视频长度、牺牲画面质量或延长处理时间来减少显存消耗,但这并非理想解决方案。
为此,FramePack 应运而生。该新架构能根据帧的重要性对其进行压缩,并汇集到一个固定大小的上下文长度内,从而极大地降低了 GPU 的显存开销。所有输入帧都经过压缩处理,以确保满足预设的上下文长度上限。研究者表示,经过优化后,FramePack 的计算成本与图像扩散模型的成本相近。
此外,FramePack 还结合了缓解“漂移”(drifting)现象的技术 —— 即视频质量随长度增加而下降的问题,从而在不显著牺牲保真度的情况下,支持生成更长的视频内容。
在硬件兼容性方面,目前 FramePack 明确要求使用支持 FP16 和 BF16 数据格式的英伟达 RTX 30、40 或 50 系列 GPU。对于图灵(Turing)架构及更早的英伟达显卡,以及 AMD 和 Intel 的硬件支持情况,目前尚未得到验证。操作系统方面,Linux 已确认在支持列表之中。考虑到 6GB 显存的需求,除了 RTX 3050 4GB 等少数型号外,市面上大多数现代 RTX 显卡都能满足运行要求。
性能方面,以 RTX 4090 为例,在启用 teacache 优化后,生成速度可达约每秒 0.6 帧。实际速度会因用户显卡型号的不同而有所差异。值得一提的是,FramePack 在生成过程中会逐帧显示画面,提供即时的视觉反馈。
目前,FramePack 所使用的模型可能有 30 帧 / 秒的上限,这或许会限制部分用户的需求,但 FramePack 的出现无疑为普通消费者进行 AI 视频创作铺平了道路,提供了一种替代昂贵第三方云服务的可行方案。即使对于非专业内容创作者,这项技术也为制作 GIF 动图、表情包等娱乐内容提供了有趣的工具。
还没有评论,来说两句吧...